
目前各大 AI 公司都通过抓取网站内容用于其 AI 训练。搜索引擎抓取内容后会给网站流量,AI 抓取内容用于训练后,像 ChatGPT 和 Google Gemini 基本不给出处,所以网站得不到流量。因此,我们要让网站禁止 AI 蜘蛛抓取。
怎样禁止 AI 抓取网站内容?目前看,还是用 robots 文件禁止访问最方便。
8月份,OpenAI 发布了他们的抓取蜘蛛的新名字:GPTBot,9月28号,Google 也发布了用于 AI 训练的专用蜘蛛名字:Google-Extended。网站可以像禁止其他蜘蛛一样,用 robots 文件禁止它们抓取:
User-agent: GPTBot
Disallow: /User-agent: Google-Extended
Disallow: /
OpenAI 的方法公布后,已经有不少大网站禁了 GPTBot 。
据 Originality.ai 统计,前1000名大网站,已经有242个禁了GPTBot,占了能检查到robots文件的933个网站的26%。其中包括 amazon,pinterest,quora,纽约时报,CNN,华盛顿邮报,路透社等。
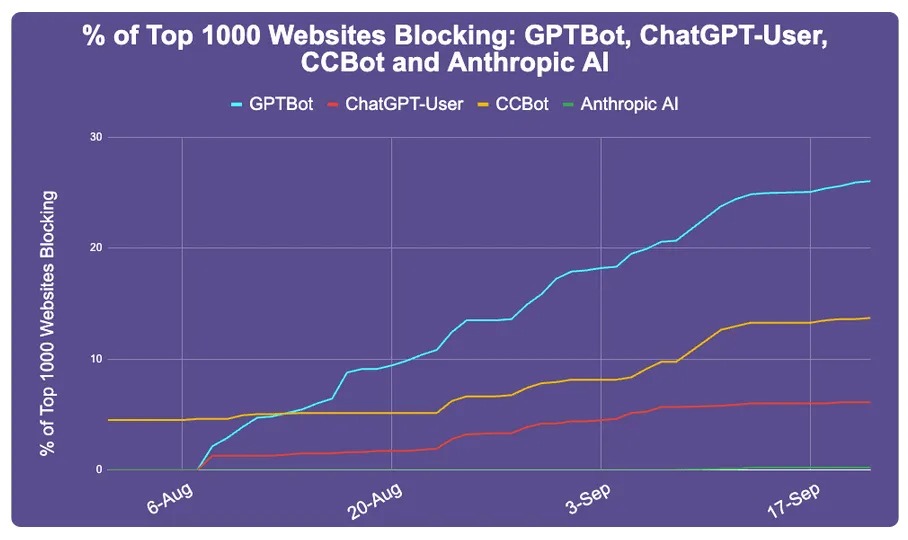
图里的 CCBot 是 Common Crawl 的蜘蛛,一个非赢利组织,是个大型网站数据库,很多 AI 是用 CC 数据库训练的,所以也被不少网站给禁了。
Google 的禁止方法才发布,还不知道成效。










我选择了在WAF里拉黑他们的UA
@秋风于渭水 你提供了另一种思路,赞。
这个提醒了我,我处理了搜索引擎爬虫,AI 爬虫倒是没想过,现在去看一下。
@dujun 这样可以过滤无效访问,减轻服务器压力,提升网站访问体验。
这些AI爬虫现在非常嚣张,来访的频率那是相当的高,我CloudFlare里直接都给过滤掉了!
@明月登楼 非常有必要禁止其访问。